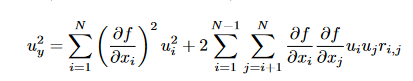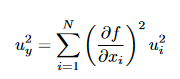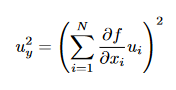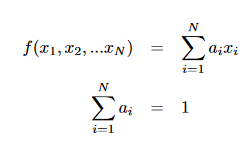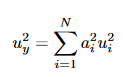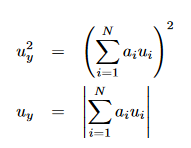That is indeed the formula. And when your input data has no internal overlap, then the weight is exactly equal to the area fraction.
Having HARP also output an actual overal area coverage fraction would be quite hard (since we then need to add a routine to create the joint area of all contributing sub areas, something we don’t have yet).
I am also not sure about the actual use. If you are really concerned in what area is actually covered or not, shouldn’t you then just be gridding at a higher spatial resolution?
And do we need really to normalize the weight by “Surface cell j”?
If we didn’t do that, then the reported weight would be a rough estimate of the number of pixels within the grid cell. At least I think.
The use is the following: when providing gridded daily files for GOME-2 and TROPOMI at the same spatial resolution (ex: 0.5), we want to provide an information on the number of observations falling into each grid cell. This number should be much higher for TROPOMI than GOME-2.
Perhaps we can do this:
harp import the L2 product in python, harp-deriving the variable area (this will be the pixel area).
Add a new variable area_inversed (with inverse pixel area values)
Then do the HARP spatial bin to L3, and do again a harp-derivation of area (this will be the grid cell area)
Finally, multiply area_inversed with area of these L3 variables
That one is actually quite simple
harp.import_product(path2l2file, “derive(area);”)
or, (when using command line tools)
harpconvert -a “derive(area);” /path/to/input_l2file /path/to/output_l2file
but the L2 file needs to have pixel bounds defined.
That won’t work. You will need to provide a dimension. e.g. derive(area {time}).
And this is also where your general approach currently breaks down, because HARP currently has no way to perform a derive(area {latitude,longitude}) (which is what you will need to get the grid cell area).
Hi Sander,
yes, I would be in favour of this. And if users do not want that the random uncertainty gets reduced with spatial binning, they could temporarily rename the variable such that it is propagated fully correlated.
I’ve been trying to implement this, but it wont work unfortunately. (at least not easily).
If you have a grid cell that only overlaps with on satellite pixel and this is only for 50% of the grid cell, then what you would have for an correlated propagation of uncertainty s is 0.5*s/0.5 = s.
But for an uncorrelated propagation, we would have sqrt(0.5*s^2)/0.5 = s/sqrt(0.5). But that doesn’t make sense. You cannot reduce the uncertainty when you have only contribution from a single satellite pixel.
This goes back to the point you raised about being able to know how many pixels contributed to a grid cell. But just knowing that number is not sufficient either, since we are dealing with an area weighted average and thus not all uncertainties contribute equally (it depends on how much of the grid cell got covered by the satellite pixel).
So, I don’t see an easy formula to use that would provide an uncorrelated propagation of uncertainties for the area weighted averaging approach.
Note that providing such a propagation for the center point attributed binning (which just takes a straight average of the satellite pixels whose center points lie within the grid cell) would still be possible. Since that will just end up being a sqrt(sum(s_i^2)/N).
My current idea on a way forward would thus be:
remove all random uncertainties when performing an average weighted spatial average (i.e. gridding based on latitude_bounds and longitude_bounds variables)
perform an uncorrelated propagation of the random uncertainties when using simple averaging based on the center points of the latitude and longitude variables.
That’s indeed an unfortunate situation. Would having an exception in the code to avoid an error reduction be an option? Even if I agree it’s not necessarily clean.
In any case, I think random errors should be kept. This is an important error component for many weak absorbers and not having it would lead to misinterpretation (it’s even worse than not reducing this component for the number of obs).
I am not sure what you mean with ‘exception in the code to avoid an error reduction’. It seems a bit handwavy to me. Do you have a specific algorithm in mind?
Also, be aware that the HARP has almost no support for uncertainty propagation at the moment. The only part where this is currently there is in the binning operations. And even there we are focussing primarily on propagation of the total uncertainty.
I am aware of the desire to keep the information regarding the systematic and random parts of the uncertainty available when propagating, but this is just not a straightforward problem.
I am very hesitant to implement half-baked solutions just to ‘have something’. I would then rather not have it in HARP directly and have users implement their own solution (outside HARP) based on their own personal preference on how to tackle this problem.
Dear Sander,
In order to implement its own solution, the user needs the observation count per grid cell (or the fractional coverage of the cell).
Is it something possible?
Kind regards
Isabelle
When talking about a users own solution, I am talking about an own solution all-the-way. HARP does not provide intermediate results (e.g. individual contributions of swaths per grid cell). Theoretically you could perform a bin_spatial on each swath individually to get such information, but I am not sure that would be efficient. So, when talking about an ‘own solution’, the user would have to calculate the observation count (or fractional coverage) per grid cell as well.
I am looking again at this problem. Because it is an unfortunate situation that for area weighted averaging the random uncertainty is now taken out.
You said that for uncorrelated propagation, with 1 satellite pixel overlapping the grid cell for 50%, the uncertainty would be sqrt(0.5*s^2)/0.5 = s/sqrt(0.5). Currently I don’t understand how you obtain this.
Starting from the general uncertainty propagation formula (see e.g., the GUM)
which reduces in case of fully random (i.e., rij=0) to
and in case of fully systematic to
In the case of averaging (arithmetic or area-weighted or some other weighting), f is some linear combination of x_i, with the coefficients adding to unity
For random uncertainty propagation one then gets
and for systematic uncertainty propagation
To calculate systematic uncertainty, actually the same calculation procedure as for the y-quantity itself is needed (one only needs to take the absolute value at the end). So I understand why it is no problem for HARP to propagate the systematic uncertainty when doing binning.
To calculate random uncertainty, the formula is different. But still the same coefficients a_i are needed as when calculating the averaged property or the systematic uncertainty. Specifically, I don’t understand why for the 1-pixel case, you obtain this sqrt(0.5*s^2)/0.5 = s/sqrt(0.5) while from the random uncertainty propagation formula above, I would obtain u_y = u_1 (since a_1 has to be 1 as the sum of a_i has to be 1).
I think you got something here. The weights for the variances also need to be squared. We are currently not doing this in HARP. So thats clearly a bug then. I will investigate how to resolve this.
Ok. The situation wasn’t as dire. We were doing uncertainty propagation already correctly for the regular (e.g. time based) binning. For the random uncertainty component we were already first multiplying by the weight and then squaring the values. And for the division we were first performing the square root and then dividing by the weight sum.
The case where we were not using a square of the weights was exactly for the case that we disabled, which was for the area weighted spatial binning. I’ve now implemented this, so it should become available in the next HARP release.